Load Balancing: Distributing Traffic Like a Pro
Load Balancing: Distributing Traffic Like a Pro
Day 3 of the 30-Day System Design Roadmap
It's Black Friday at 11:59 PM. Your e-commerce site has 50,000 concurrent shoppers frantically adding items to their carts. One server melts down under the pressure while three others sit idle. Sound like a nightmare? This is exactly what happens without proper load balancing.
I've watched systems crumble and systems soar, and the difference often comes down to one thing: how well you distribute traffic. Today, we're diving deep into load balancing—the unsung hero that keeps the internet running smoothly.
The Traffic Distribution Problem
Let me paint you a picture. Imagine you're running a popular food delivery app. You've scaled horizontally (as we discussed in Day 2), so you now have five application servers instead of one. Great! But here's the problem: how do your users' requests get distributed across these servers?
Without a load balancer, you'd have chaos:
- Some servers get hammered while others sit idle
A Load Balancer Saves the Day
A load balancer sits between your users and your servers, intelligently distributing incoming traffic. Think of it as a traffic cop at a busy intersection, but smarter—it knows which roads are congested, which ones are closed for maintenance, and which routes get you to your destination fastest.
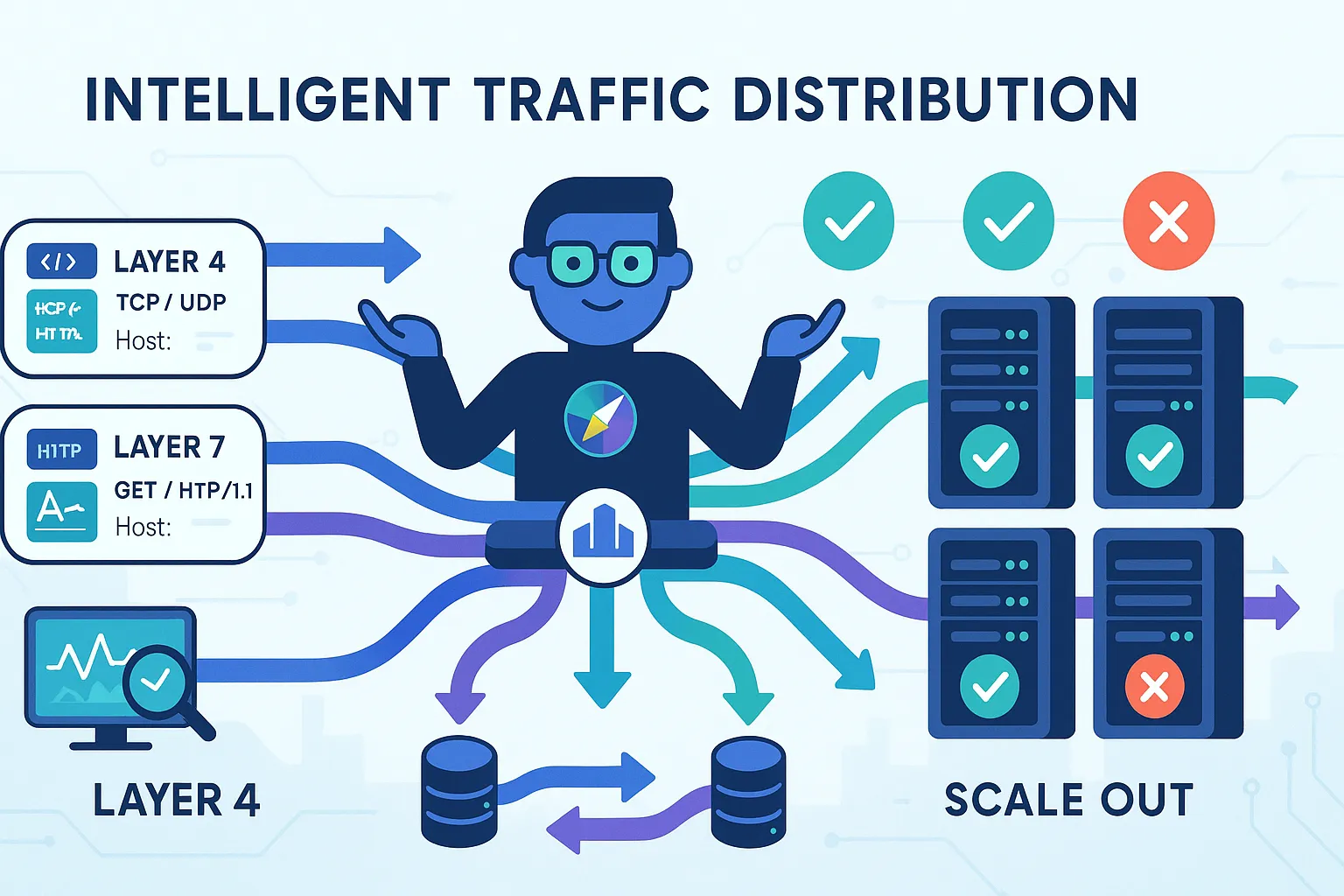
Load Balancer Types: Layer 4 vs Layer 7
This is where things get interesting. Not all load balancers are created equal. The layer at which they operate determines what information they can use to make routing decisions.
Layer 4 Load Balancing: The Speed Demon
Layer 4 load balancers operate at the transport layer (TCP/UDP). They make routing decisions based on IP addresses and port numbers—that's it. They don't peek inside the actual data packets.
Real-World Example: Financial Trading Platform
I consulted for a high-frequency trading platform where every millisecond mattered. They needed to distribute millions of requests per second across their order processing servers.
We implemented an Layer 4 load balancer using HAProxy. Here's why it worked:
# HAProxy Layer 4 Configuration
frontend trading_frontend
bind *:8080
mode tcp
default_backend trading_servers
backend trading_servers
mode tcp
balance roundrobin
server server1 10.0.1.10:8080 check
server server2 10.0.1.11:8080 check
server server3 10.0.1.12:8080 checkThe Result: Sub-millisecond routing decisions, handling 2 million requests per second with minimal latency overhead.
When to Use Layer 4:
- Ultra-low latency requirements
Layer 7 Load Balancing: The Smart Router
Layer 7 load balancers operate at the application layer. They can inspect HTTP headers, cookies, URL paths—even the request body if needed. This makes them incredibly powerful for complex routing scenarios.
Real-World Example: Multi-Tenant SaaS Platform
Let's say you're building a project management SaaS like Asana or Monday.com. Different customers have wildly different usage patterns:
- Enterprise customer A: 10,000 users, needs dedicated servers
Here's how Layer 7 load balancing solves this:
# NGINX Layer 7 Configuration
http {
upstream enterprise_tier {
server 10.0.2.10:8080;
server 10.0.2.11:8080;
}
upstream standard_tier {
server 10.0.3.10:8080;
server 10.0.3.11:8080;
server 10.0.3.12:8080;
}
server {
listen 80;
# Route enterprise customers to dedicated servers
location / {
if ($http_x_customer_tier = "enterprise") {
proxy_pass http://enterprise_tier;
}
proxy_pass http://standard_tier;
}
# API endpoints to specialized servers
location /api/reports {
proxy_pass http://enterprise_tier;
}
# Static assets to CDN
location /static/ {
proxy_pass http://cdn_servers;
}
}
}When to Use Layer 7:
- Content-based routing (API vs web vs mobile)
Load Balancing Algorithms: Choosing Your Strategy
Now let's talk about the real magic: how load balancers decide which server gets the next request. This is where the art meets science.
1. Round Robin: The Classic
Round robin distributes requests sequentially across all servers. Server 1, Server 2, Server 3, back to Server 1.
Code Example:
class RoundRobinLoadBalancer:
def __init__(self, servers):
self.servers = servers
self.current_index = 0
def get_next_server(self):
server = self.servers[self.current_index]
self.current_index = (self.current_index + 1) % len(self.servers)
return server
# Usage
lb = RoundRobinLoadBalancer([
'server1.example.com',
'server2.example.com',
'server3.example.com'
])
for _ in range(6):
print(f"Route to: {lb.get_next_server()}")
# Output:
# Route to: server1.example.com
# Route to: server2.example.com
# Route to: server3.example.com
# Route to: server1.example.com
# Route to: server2.example.com
# Route to: server3.example.comWhen It Works Well:
- All servers have identical specs
When It Falls Apart:
2. Weighted Round Robin: Playing Favorites
This is round robin's smarter sibling. You assign weights to servers based on their capacity.
class WeightedRoundRobinLoadBalancer:
def __init__(self, servers_with_weights):
"""
servers_with_weights: [('server1', 5), ('server2', 3), ('server3', 2)]
"""
self.servers = []
for server, weight in servers_with_weights:
self.servers.extend([server] * weight)
self.current_index = 0
def get_next_server(self):
server = self.servers[self.current_index]
self.current_index = (self.current_index + 1) % len(self.servers)
return server
# Usage
lb = WeightedRoundRobinLoadBalancer([
('powerful-server.com', 5), # Gets 50% of traffic
('medium-server.com', 3), # Gets 30% of traffic
('small-server.com', 2) # Gets 20% of traffic
])Real-World Win: After implementing weighted round robin at that video streaming company, we gave the weak server weight 2 and the powerful servers weight 5 each. CPU utilization balanced perfectly across all servers.
3. Least Connections: The Fair Distributor
This algorithm routes new requests to the server with the fewest active connections. Perfect when requests have varying durations.
import heapq
from dataclasses import dataclass, field
from typing import Any
@dataclass(order=True)
class Server:
active_connections: int
address: str = field(compare=False)
class LeastConnectionsLoadBalancer:
def __init__(self, servers):
self.servers = [Server(0, addr) for addr in servers]
heapq.heapify(self.servers)
def get_next_server(self):
# Get server with least connections
server = heapq.heappop(self.servers)
server.active_connections += 1
heapq.heappush(self.servers, server)
return server.address
def release_connection(self, server_address):
# Find and update server
for server in self.servers:
if server.address == server_address:
server.active_connections -= 1
heapq.heapify(self.servers)
break
# Usage
lb = LeastConnectionsLoadBalancer([
'server1.example.com',
'server2.example.com',
'server3.example.com'
])
# Simulate requests
print(lb.get_next_server()) # server1
print(lb.get_next_server()) # server2
print(lb.get_next_server()) # server3
lb.release_connection('server1.example.com')
print(lb.get_next_server()) # server1 (now has 0 connections again)Perfect For:
- WebSocket connections that last minutes or hours
4. Least Response Time: The Performance Optimizer
Routes to the server with the lowest average response time AND fewest active connections.
import time
from collections import defaultdict
class LeastResponseTimeLoadBalancer:
def __init__(self, servers):
self.servers = servers
self.active_connections = defaultdict(int)
self.response_times = defaultdict(list)
self.max_samples = 100
def get_average_response_time(self, server):
times = self.response_times[server]
if not times:
return 0
return sum(times) / len(times)
def calculate_score(self, server):
"""Lower score = better server"""
avg_response = self.get_average_response_time(server)
connections = self.active_connections[server]
return avg_response * (connections + 1)
def get_next_server(self):
best_server = min(self.servers, key=self.calculate_score)
self.active_connections[best_server] += 1
return best_server
def record_response_time(self, server, response_time):
self.response_times[server].append(response_time)
# Keep only recent samples
if len(self.response_times[server]) > self.max_samples:
self.response_times[server].pop(0)
self.active_connections[server] -= 1
# Usage
lb = LeastResponseTimeLoadBalancer([
'server1.example.com',
'server2.example.com'
])
# Simulate traffic
server = lb.get_next_server()
start = time.time()
# ... process request ...
lb.record_response_time(server, time.time() - start)War Story: An API platform I worked with was experiencing mysterious slowdowns. Some servers were fast, others slow. We switched from round robin to least response time, and the system automatically started avoiding the slow servers. Turned out one server had a dying disk—the load balancer detected the problem before our monitoring did!
5. IP Hash: Session Affinity Done Right
Routes clients to servers based on their IP address hash. The same client always goes to the same server.
import hashlib
class IPHashLoadBalancer:
def __init__(self, servers):
self.servers = servers
def get_server_for_ip(self, client_ip):
# Create consistent hash of IP
hash_value = int(hashlib.md5(client_ip.encode()).hexdigest(), 16)
server_index = hash_value % len(self.servers)
return self.servers[server_index]
# Usage
lb = IPHashLoadBalancer([
'server1.example.com',
'server2.example.com',
'server3.example.com'
])
# Same IP always routes to same server
print(lb.get_server_for_ip('192.168.1.100')) # server2
print(lb.get_server_for_ip('192.168.1.100')) # server2
print(lb.get_server_for_ip('192.168.1.100')) # server2
print(lb.get_server_for_ip('192.168.1.101')) # server1Critical Use Case: Shopping carts! If user sessions are stored in server memory, you need IP hash to ensure users always hit the same server. (Though honestly, you should use Redis for session storage instead.)
Health Checks and Failover: The Safety Net
This is where amateur load balancers become professional ones. Health checks ensure you never send traffic to a dead or dying server.
Implementing Robust Health Checks
import requests
import time
from threading import Thread
from enum import Enum
class ServerStatus(Enum):
HEALTHY = "healthy"
UNHEALTHY = "unhealthy"
CHECKING = "checking"
class HealthCheckLoadBalancer:
def __init__(self, servers, health_check_interval=10):
self.servers = {server: ServerStatus.HEALTHY for server in servers}
self.health_check_interval = health_check_interval
self.start_health_checks()
def check_server_health(self, server):
"""Perform actual health check"""
try:
# Try to connect to health endpoint
response = requests.get(
f"http://{server}/health",
timeout=2
)
if response.status_code == 200:
# Additional checks
data = response.json()
if data.get('cpu_usage', 0) > 90:
return ServerStatus.UNHEALTHY
if data.get('memory_usage', 0) > 95:
return ServerStatus.UNHEALTHY
return ServerStatus.HEALTHY
else:
return ServerStatus.UNHEALTHY
except Exception as e:
print(f"Health check failed for {server}: {e}")
return ServerStatus.UNHEALTHY
def health_check_loop(self):
"""Background thread that continuously checks server health"""
while True:
for server in self.servers:
self.servers[server] = self.check_server_health(server)
time.sleep(self.health_check_interval)
def start_health_checks(self):
thread = Thread(target=self.health_check_loop, daemon=True)
thread.start()
def get_healthy_servers(self):
return [
server for server, status in self.servers.items()
if status == ServerStatus.HEALTHY
]
def get_next_server(self):
healthy_servers = self.get_healthy_servers()
if not healthy_servers:
raise Exception("No healthy servers available!")
# Use round robin on healthy servers
return healthy_servers[0] # Simplified for example
# Usage
lb = HealthCheckLoadBalancer([
'server1.example.com:8080',
'server2.example.com:8080',
'server3.example.com:8080'
], health_check_interval=5)
# Health checks run in background
time.sleep(10)
print("Healthy servers:", lb.get_healthy_servers())Multi-Level Health Checks
Don't just check if the server responds—check if it's actually healthy:
# Health endpoint implementation (Flask example)
from flask import Flask, jsonify
import psutil
app = Flask(__name__)
@app.route('/health')
def health_check():
"""Comprehensive health check"""
# Check CPU
cpu_percent = psutil.cpu_percent(interval=1)
if cpu_percent > 90:
return jsonify({
'status': 'unhealthy',
'reason': 'High CPU usage',
'cpu_usage': cpu_percent
}), 503
# Check memory
memory = psutil.virtual_memory()
if memory.percent > 95:
return jsonify({
'status': 'unhealthy',
'reason': 'High memory usage',
'memory_usage': memory.percent
}), 503
# Check database connectivity
try:
db.ping()
except Exception as e:
return jsonify({
'status': 'unhealthy',
'reason': 'Database connection failed',
'error': str(e)
}), 503
# Check disk space
disk = psutil.disk_usage('/')
if disk.percent > 90:
return jsonify({
'status': 'degraded',
'reason': 'Low disk space',
'disk_usage': disk.percent
}), 200
return jsonify({
'status': 'healthy',
'cpu_usage': cpu_percent,
'memory_usage': memory.percent,
'disk_usage': disk.percent
}), 200Practical Exercise: E-Commerce Load Balancing Strategy
Let's design a complete load balancing strategy for an e-commerce site. Here's the scenario:
The Business:
- Peak traffic: Black Friday (100,000 concurrent users)
The Architecture
[DNS Load Balancing]
|
+-------------------+-------------------+
| | |
[US-East Region] [US-West Region] [EU Region]
| | |
[Layer 7 LB (NGINX)] [Layer 7 LB] [Layer 7 LB]
|
+-----------+-----------+-----------+
| | | |
[Web App] [API] [Checkout] [Search]
(3 servers) (5 servers) (2 servers) (2 servers)Configuration Strategy
1. Geographic Load Balancing (DNS Level)
# Route53 / CloudFlare configuration
us-east.example.com A 52.1.1.1 (Latency-based routing)
us-west.example.com A 54.1.1.1 (Latency-based routing)
eu.example.com A 34.1.1.1 (Latency-based routing)
# Automatic failover
www.example.com -> Primary: us-east, Failover: us-west2. Application Layer (NGINX Configuration)
# /etc/nginx/nginx.conf
http {
# Define upstream server pools
# Web application servers - Least Connections
upstream web_app {
least_conn;
server 10.0.1.10:8080 weight=3;
server 10.0.1.11:8080 weight=3;
server 10.0.1.12:8080 weight=2; # Older server
# Health checks
health_check interval=5s fails=3 passes=2;
}
# API servers - Least Response Time
upstream api_servers {
least_conn;
server 10.0.2.10:8080;
server 10.0.2.11:8080;
server 10.0.2.12:8080;
server 10.0.2.13:8080;
server 10.0.2.14:8080;
health_check uri=/health interval=3s;
}
# Checkout servers - IP Hash (session affinity)
upstream checkout_servers {
ip_hash;
server 10.0.3.10:8080;
server 10.0.3.11:8080;
# More aggressive health checks for critical service
health_check interval=2s fails=2;
}
# Search servers - Round Robin (stateless)
upstream search_servers {
server 10.0.4.10:8080;
server 10.0.4.11:8080;
health_check interval=5s;
}
# Rate limiting zones
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=100r/s;
limit_req_zone $binary_remote_addr zone=checkout_limit:10m rate=10r/s;
# Main server block
server {
listen 80;
listen 443 ssl http2;
server_name www.example.com;
# SSL configuration
ssl_certificate /etc/nginx/ssl/cert.pem;
ssl_certificate_key /etc/nginx/ssl/key.pem;
# Security headers
add_header X-Frame-Options "SAMEORIGIN";
add_header X-Content-Type-Options "nosniff";
# Static assets - direct serving with caching
location /static/ {
alias /var/www/static/;
expires 30d;
add_header Cache-Control "public, immutable";
}
# API endpoints - rate limited
location /api/ {
limit_req zone=api_limit burst=20 nodelay;
proxy_pass http://api_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# Timeouts
proxy_connect_timeout 5s;
proxy_send_timeout 10s;
proxy_read_timeout 10s;
}
# Checkout - session affinity + strict rate limiting
location /checkout/ {
limit_req zone=checkout_limit burst=5;
proxy_pass http://checkout_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
# Longer timeouts for payment processing
proxy_read_timeout 30s;
# No caching for checkout
add_header Cache-Control "no-store, no-cache, must-revalidate";
}
# Search endpoints
location /search/ {
proxy_pass http://search_servers;
proxy_set_header Host $host;
# Cache search results
proxy_cache search_cache;
proxy_cache_valid 200 5m;
proxy_cache_key "$scheme$request_method$host$request_uri";
}
# Admin panel - restricted access
location /admin/ {
allow 203.0.113.0/24; # Office IP range
deny all;
proxy_pass http://web_app;
proxy_set_header Host $host;
}
# Main web application
location / {
proxy_pass http://web_app;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# Enable HTTP/2 server push
http2_push_preload on;
}
}
}Monitoring and Auto-Scaling
# Auto-scaling logic based on metrics
import boto3
from dataclasses import dataclass
@dataclass
class ScalingPolicy:
min_instances: int
max_instances: int
target_cpu: float
target_connections_per_instance: int
class LoadBalancerAutoScaler:
def __init__(self, policies):
self.policies = policies
self.ec2 = boto3.client('ec2')
self.elb = boto3.client('elbv2')
def should_scale_up(self, service_name, current_metrics):
policy = self.policies[service_name]
# Check CPU utilization
if current_metrics['avg_cpu'] > policy.target_cpu:
return True
# Check connections per instance
total_connections = current_metrics['total_connections']
num_instances = current_metrics['num_instances']
if total_connections / num_instances > policy.target_connections_per_instance:
return True
return False
def should_scale_down(self, service_name, current_metrics):
policy = self.policies[service_name]
if current_metrics['num_instances'] <= policy.min_instances:
return False
# Only scale down if consistently underutilized
if (current_metrics['avg_cpu'] < policy.target_cpu * 0.5 and
current_metrics['total_connections'] <
current_metrics['num_instances'] * policy.target_connections_per_instance * 0.3):
return True
return False
# Configure policies
policies = {
'api': ScalingPolicy(
min_instances=3,
max_instances=20,
target_cpu=70.0,
target_connections_per_instance=1000
),
'checkout': ScalingPolicy(
min_instances=2,
max_instances=10,
target_cpu=60.0, # Lower threshold for critical service
target_connections_per_instance=500
)
}Common Pitfalls and How to Avoid Them
Pitfall #1: Ignoring Session Persistence
The Problem: Users keep getting logged out because each request goes to a different server with different session storage.
The Fix: Use one of these approaches:
1. Sticky sessions (IP hash or cookie-based routing)
2. Centralized session store (Redis/Memcached) - Recommended
3. JWT tokens (stateless authentication)
# Redis session store example
import redis
from flask import Flask, session
from flask_session import Session
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'redis'
app.config['SESSION_REDIS'] = redis.from_url('redis://localhost:6379')
Session(app)
# Now sessions work across all servers!Pitfall #2: Not Testing Failover
The Problem: Your health checks look good in testing, but when a server actually fails in production, everything breaks.
The Fix: Chaos engineering! Randomly kill servers in your staging environment.
# Chaos monkey script
#!/bin/bash
# randomly_kill_server.sh
SERVERS=("server1" "server2" "server3")
RANDOM_SERVER=${SERVERS[$RANDOM % ${#SERVERS[@]}]}
echo "Killing $RANDOM_SERVER to test failover..."
ssh $RANDOM_SERVER "sudo systemctl stop app.service"
echo "Waiting 60 seconds to observe behavior..."
sleep 60
echo "Restoring $RANDOM_SERVER..."
ssh $RANDOM_SERVER "sudo systemctl start app.service"Pitfall #3: Cascading Failures
The Problem: One slow server causes the load balancer to route all traffic to other servers, which then become overloaded and crash. Soon, everything is down.
The Fix: Implement circuit breakers!
from datetime import datetime, timedelta
from enum import Enum
class CircuitState(Enum):
CLOSED = "closed" # Normal operation
OPEN = "open" # Failing, don't send traffic
HALF_OPEN = "half_open" # Testing if recovered
class CircuitBreaker:
def __init__(self, failure_threshold=5, timeout=60):
self.failure_threshold = failure_threshold
self.timeout = timeout
self.failures = 0
self.last_failure_time = None
self.state = CircuitState.CLOSED
def call(self, func):
if self.state == CircuitState.OPEN:
if (datetime.now() - self.last_failure_time).seconds > self.timeout:
self.state = CircuitState.HALF_OPEN
else:
raise Exception("Circuit breaker is OPEN")
try:
result = func()
if self.state == CircuitState.HALF_OPEN:
self.state = CircuitState.CLOSED
self.failures = 0
return result
except Exception as e:
self.failures += 1
self.last_failure_time = datetime.now()
if self.failures >= self.failure_threshold:
self.state = CircuitState.OPEN
raise e
# Usage with load balancer
class ResilientLoadBalancer:
def __init__(self, servers):
self.circuit_breakers = {
server: CircuitBreaker(failure_threshold=3, timeout=30)
for server in servers
}
def send_request(self, server, request):
try:
return self.circuit_breakers[server].call(
lambda: self._make_request(server, request)
)
except Exception as e:
# Try next server
return self._retry_with_another_server(request, exclude=server)Key Takeaways
After designing and debugging load balancers for years, here's what I want you to remember:
1. Layer 4 for speed, Layer 7 for intelligence: Choose based on your specific needs.
2. Health checks are non-negotiable: Don't just check if the server responds—check if it's actually healthy.
3. Algorithm matters less than you think: Round robin works great 80% of the time. Focus on proper health checks and failover first.
4. Session management is critical: Use Redis or similar for session storage, not in-memory session storage.
5. Monitor everything: Track not just server health, but also request distribution, response times, and error rates per server.
6. Test failure scenarios: Your load balancer's real value shows when things go wrong.
What's Next?
We've mastered traffic distribution, but here's the thing: even perfectly balanced traffic hits your database eventually. And databases don't scale horizontally as easily as application servers.
In our next post, we'll tackle database design and optimization—how to structure your data, when to use SQL vs NoSQL, and how to avoid the database becoming your bottleneck.
---
Resources:
Want to practice? Try implementing a simple load balancer in your favorite language. Start with round robin, add health checks, then level up to least connections. You'll learn more in an afternoon of coding than in weeks of reading!
Related Articles
The Complete Guide to Application Scalability: When Your App Outgrows Its Server
Learn how to effectively scale your application with real-world examples, strategies, and tools. Understand when to scale up vs. scale out, and avoid common pitfalls.
Database Design Patterns: Choosing the Right Data Store
Master database selection strategies, from SQL to NoSQL. Learn ACID properties, CAP theorem, and design a production-ready database schema for a social media platform.